|
libwt
1.0.0
A C++ library for the continous wavelet transform.
|
|
libwt
1.0.0
A C++ library for the continous wavelet transform.
|
The continuous wavelet transfrom of a (possibly complex) signal 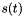 , given a mother wavelet
, given a mother wavelet 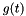 , at time
, at time 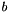 and scale
and scale 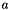 is given by
is given by
![\[m(b,a) = \int_{-\infty}^{\infty}\bar{s}(t)\,\frac{1}{a}g\left(\frac{t-b}{a}\right)\,dt\,,\]](form_22.png)
see Wavelets for a list of all implemented wavelets. For each proper (analysis) wavelet[2] 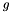 , there exists a second (synthesis) wavelet
, there exists a second (synthesis) wavelet 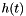 that reconstructs the signal as
that reconstructs the signal as
![\[s(t) = \frac{1}{c_{g,h}}\,\int_{0}^{\infty}\,\frac{da}{a}\,\int_{-\infty}^{\infty}\,dt\, \bar{m}(b,a)\,\frac{1}{a}h\left(\frac{b-t}{a}\right)\,,\]](form_26.png)
where 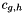 is a normalization constant depending on the chosen wavelet pair
is a normalization constant depending on the chosen wavelet pair 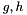 .
.
In general, using the FFT convolution algorihtm to perform a wavelet transform of a signal of length 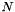 at
at 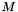 scales, the computational costs (time) are generally
scales, the computational costs (time) are generally 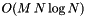 . Hence the tranform can get pretty slow for long signals. Exploiting, that wavelets are usually well localized in the time and frequency domain, allows for a significant reduction of the computational costs of the transform. This gain, however, is a constant factor which means, that the general dependency of the costs on the signal length and number of scales remains in the order of .
. Hence the tranform can get pretty slow for long signals. Exploiting, that wavelets are usually well localized in the time and frequency domain, allows for a significant reduction of the computational costs of the transform. This gain, however, is a constant factor which means, that the general dependency of the costs on the signal length and number of scales remains in the order of .
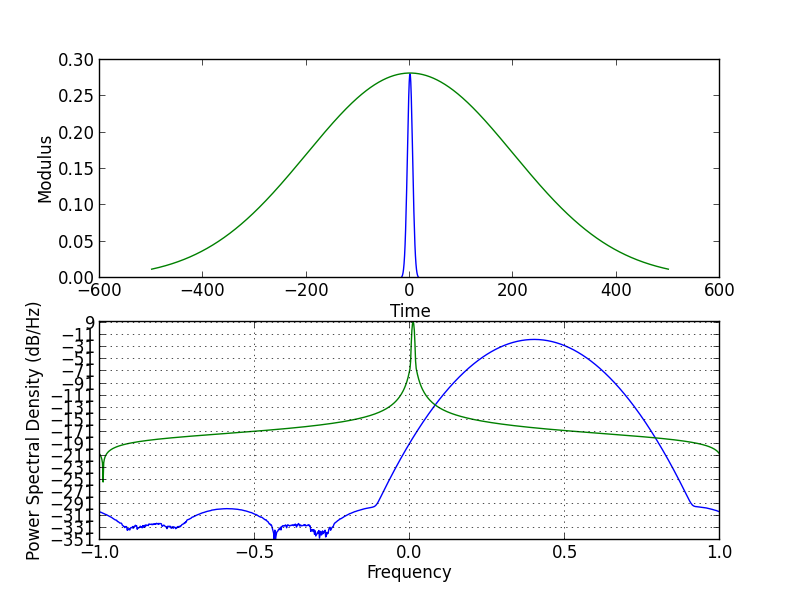
At small scales, the time localization of the wavelet can be exploited (see figure above, upper panel). There the scaled wavelet can be approximated well by a filter kernel beeing much shorter than the time series. The convolution of the (short) scaled wavelet with the (long) time series can then be performed efficiently by using the well known "overlap-add" method[3].
At large scales (figure above, lower panel), the frequency localization of the wavelet can be exploited. There the high-frequency components of the wavelet are basically zero and the convolution of these long but low-frequency wavelets can be performed in an interleaved manner on sub-samples of the signal. This approach is related to the "algorithm a trois"[1] for the wavelet transform on dyadic grids.
In both cases, a time series of length will be processed in terms of 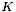 signals of length
signals of length 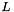 , such that
, such that 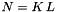 (assuming the signal length can be factored that way, if not the signal will be zero-padded). Hence the computational costs of the FFT convolutions to obtain a single "voice" (wavelet trasform at a specific frequency/scale) are
(assuming the signal length can be factored that way, if not the signal will be zero-padded). Hence the computational costs of the FFT convolutions to obtain a single "voice" (wavelet trasform at a specific frequency/scale) are 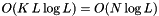 instead of
instead of 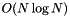 . If
. If 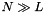 the costs of the wavelet transform can be reduced significantly.
the costs of the wavelet transform can be reduced significantly.
 1.8.9.1
1.8.9.1

